

1 Overview 综述
In computer vision, superpixels help to reduce the number of image primitives for subsequent processing. It converts the pixel-level image to the district-level image, which can be treated as the abstraction of original image information. There are many methods to generate superpixels but only have few attempts to generate it using deep neural networks. A recent study from Pennsylvania State University proposed a fully convolutional network to generate superpixels. The paper Superpixel Segmentation with Fully Convolutional Networks was published on CVPR2020. The state-of-art method of superpixels generation would become much more popular in the future.
在计算机视觉中,超像素有助于减少用于后续处理的图像基元的数量。 它将像素级别的图像转换为区域级别的图像,可以将其视为原始图像信息的抽象。 生成超像素的方法有很多,但是只有很少的尝试使深度神经网络生成超像素。最近一篇论文《Superpixel Segmentation with Fully Convolutional Networks》,宾大州立的研究人员提出了使用了全卷积网络来生成超像素的方式,论文发表在CVPR2020中。这种全新的超像素生成方式,给其应用带来更广阔的空间。
Researchers pointed out the challenges of using a fully convolutional network to generate superpixels. The standard convolution operation is defined on regular grids and becomes inefficient when applied to superpixels. Therefore, the author used a novel method that accelerates the superpixels generation.
作者在文中指出,使用全卷积生成超像素的挑战在于:“标准卷积运算是在规则网格上定义的,当应用于超像素时其效率会变的很低”。所以本文作者运用了一种更高效的方式,可以使用全卷积网络来快速生成超像素。
1.1 Summary 概要
In this paper:
- The author first proposed a method to generate superpixels with a fully convolutional network. According to experimental results, their approach is comparable to state-of-the-art superpixel segmentation performance. Besides, the superpixels generation speed is 50fps, which is faster than the previous research study.
- The author second developed an architecture for dense prediction tasks based on predicted superpixels, which can boost the performance to generate high-resolution outputs. The architecture is combined with a superpixels generation into popular network architecture for stereo matching. In this way, it helps improve disparity estimation accuracy.
在这篇论文:
- 作者首先提出了一种用全卷积网络生成超像素的方式。通过结果来看,本方法可以和当今最流行的方法媲美,同时生成超像素的速度可以达到50fps。
- 其次,作者提出可以将生成的超像素用于后续的密度预测任务,并且有助于得到更好的结果。其思路是,将用于生成超像素的全卷积网络与主流的立体匹配网络相结合,帮助立体匹配网络产生更准确的差距。
1.2 Advantages 优势
In my opinion, there are two points I can learn from it:
- First, using a fully convolutional network to fast generate superpixels by solving primary inefficient issues. In the future, I can try to use different deep neural networks to generate superpixels. For example, diverse architectures or operators. In this paper, the fully convolutional network is a simple encoder-decoder architecture. I am surprised that why so many researchers could not think of such a simple idea. Most of the time, make complicated things more complect may not be the right choice. I should consider the fundamental motivations behind things. For example, in this paper, the author pointed out: “Superpixel is inherently an over-segmentation method. As one of the main purposes of our superpixel method is to perform the detail-preserved downsampling/upsampling to assist the downstream network, it is more important to capture spatial coherence in the local region.” Based on this motivation, the author first inspired an initialization strategy from traditional superpixel algorithms. Then they used a fixed regular grid to find out the local region information rather than compute all pixel-superpixel paris. Finally, using the advantages of a fully convolutional network, Superpixel assigned as the highest probability of region pixels. In the end, based on this design idea, it successfully solves inefficient when using deep neural networks to generate superpixels.
- Second, the fully convolutional network used to generate superpixels can be more easily combined with many deep neural networks to improve the overall performance in different computer vision tasks. For example, the author tried superpixels in the dense prediction tasks, improving stereo matching performance. Therefore, could this idea be applied to different computer vision tasks to improve related deep neural network performance?
个人认为,本文有两个地方可以借鉴:
- 第一,通过解决主要的低效率问题,使全卷积网络可以快速生成超像素。未来可以尝试用更多不同的深度神经网络去生成超像素。比如,不同的结构或者不同的算子。在本文中的全卷积网络是一个编码器-解码器架构。我很好奇,这么通用并且简答的架构,为什么很多研究人员想不到?很多时候,将复杂的结构变的更复杂,可能不如先想明白事情的本质。比如说,作者的在文中指出超像素的本质是:“一种过度分割的方法。其目的是:“为了保留下采样/上采的细节,这样可以辅助下游网络去更好的捕获在某些区域的空间连贯性。”基于这样的目的,作者首先借鉴初始化步骤在传统的超像素生成算法中。其次,利用局部而非全局信息。最后,结合全卷积网络的优势找出局部信息中最有可能点作为超像素的点。这样的设计理念,成功的解决的了用深度神经网络生成超像素的低效问题。
- 第二, 用于生成超像素的全卷积网络,可以更容易的和很多深度神经网络结合,去提升深度神经网络在不同计算机视觉任务中的性能。例如,作者在文本中只在密度预测任务中,尝试用超像素去辅助主流的立体匹配网络提升其性能。所以,是否可以将这样的想法运用到不同计算机视觉任务中,去提升相应的深度神经网络的性能?
1.3 Disadvantages 劣势
In my opinion, two points need to pay attention to:
- First, they used a fully convolutional network to generate superpixels. And they took advantage of 3 x 3 regular grid (total nine grid cells included). In other words, such local information only produces a fixed number of superpixels. If there are some cases or data, it is hard to get more superpixels and control the generated superpixel.
- Second, when the fully convolutional network is used to generate superpixels combined with deep neural networks, it could reduce the output efficiency even though it may make results better. In this paper, the author stated that the superpixels generation speed is 50fps. Tt possible that the overall inference speed is about 50fps or even lower after combining all. Therefore, the idea may be hard to apply to many applications if there is no better way to solve them.
个人认为,本文有几个地方需要注意:
- 第一,在作者提出利用全卷积网络生成超像素的方式中,所用的局部信息只有一个3 x 3 区域(也就是9个网格包域)。也就是说,这样局部信息只能生成固定的超像素。如果遇到特定的情况或者特定的数据,很难去生成更多的超像素,同时也很难去控制生成指定数量的超像素。
- 第二, 将生成超像素的全卷积网络和主流深度神经网络结合,在提升性能的同时,可能会降低其输出的效率。本文中,作者指出生成超像素的速度可以达到50fps。也就说,如果将全卷积网络生成超像素和主流深度神经网络结合,那么其输出结果的效率大概率会被锁定在50fps左右或者更低。因此,如果找不到一种办法可以加速全卷积网络生成超像素,那么可能很难应用到实际中。
1.4 Future 后续
The author will use the same architecture to generate superpixels that combine with other deep neural networks. It may help with many computer vision subtasks: target segmentation and optical flow estimation tasks. Also, the author will explore more applications that can introduce superpixels.
作者在提出,会将生成超像素的全卷积网络和不同主流深度神经网络结合, 去尝试处理不同的计算机视觉子任务:目标分割和光流估计任务。并且,作者会探索不同的方式去让超像素得到更广的应用。
In my opinion, the first point raised by the author is the same as what I thought before (1.2 Advantages, second point). When I find different superpixels application scenarios, I can try to use various deep neural networks to generate superpixels. For example, For example, diverse architectures or operators. (1.2 Advantages, first point).
个人认为,作者提出的第一点和我在之前想的(1.2 优势,第二点)一样。除此以外,我觉得当找到不同的超像素应用场景的时候,可以尝试用更多不同的深度神经网络去生成超像素。比如,不同的结构或者不同的算子(1.2 优势,第一点)。
2 Highlight Details 重点细节
2.1 SpixelFCN
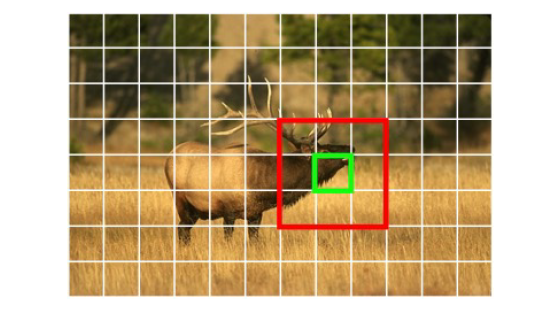
First of all, researchers proposed a fully convolutional network to generate superpixels, SpixelFCN. Unlike the traditional way of generating superpixels, the fully convolutional network only uses the local information to generate superpixels. The purpose of this is to reduce unnecessary computation. As shown in the figure below, there are many pixels in the green box and only collect the 3 x 3 red boxes area. By learning a soft association map, the pixels with the highest probability in the nine grid cells as superpixels.
本篇论文的第一个亮点是提出了一个全卷积网络生成超像素SpixelFCN。与传统的超像素的生成方式不同,利用全卷积网络生成超像素仅仅关注局部信息。这样做的目的是为了减少不必要的计算。如下图所示,绿框中有很多像素点只收索附近3 x 3红框区域内的信息。最终在9个网格包域中,通过学习到到的一个软关联图,将域中最高概率的像素点设置为超像素点。
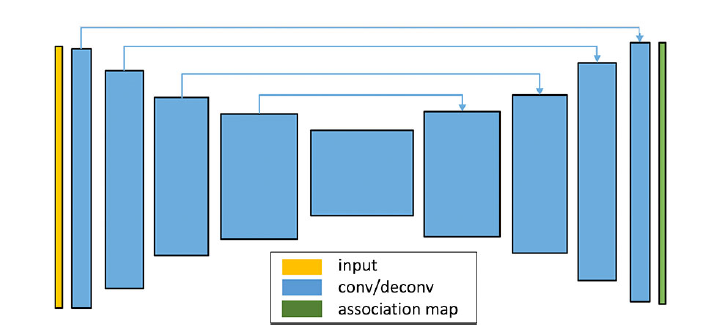
Here, the soft association map can be learned as a fully convolutional network with a simple encoder-decoder architecture. As shown in the figure below, a schematic diagram and please refer to the paper’s supplementary materials for information.
这里的软关联图可以通过一个拥有编码器-解码器架构的全卷积网络学习获得。如下图所示,一个简答的示意图,具体的结构参考原论文的补充材料。
The author also compared with “Superpixel Sampling Networks” (SSN) in ECCV2018. As shown in the figure below, although they both introduced the fully convolutional network into the design, the author in this paper pointed out their architecture has fundamentally different than SSN. The former uses the fully convolutional network as a tool. And then, it uses K-Means to obtain global information to generate superpixels. The method proposed in this paper generates superpixels with only a fully convolutional network.
作者同时还比较了在ECCV2018中的”Superpixel Sampling Networks”(SSN)。如下图所示,虽然都是引入全卷积网络的想法,但是作者提出的结构和SSN有本质的不用。前者只是把全卷积网络用做一个工具,最后还是要通过K-Means来获取全局信息生成超像素。而后者,仅仅用一个简单的全卷积网络就可以搞定了,不需要其他复杂的计算。

In the paper, a generated superpixel is composed of two vectors. One represents the superpixel attributes, and the other represents the position of the superpixel. As in the following formula:
论文中,生成的超像素有两个向量组成,一个是代表超像素额属性,另一个代表超像素的位置。如下面公式:
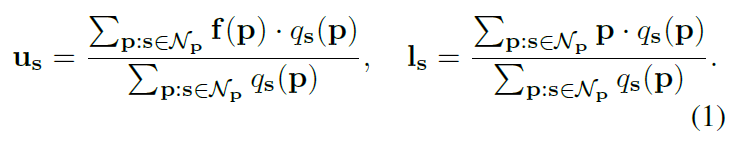
The pixels can be reconstructed through the above two vectors. As is the following formula:
通过这向量可以重建像素点,如如下面公式:
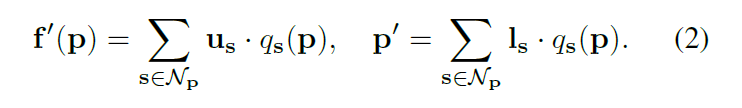
Finally, the original pixels and reconstructed pixels can be written as a loss function. As in the following formula, the first term represents similarity, and the second term represents compactness of space:
最后可以将原始像素点和重建像素点,写成一个损失函数。如下面公式,第一项代表相似性,第二项代表空间的紧凑性:
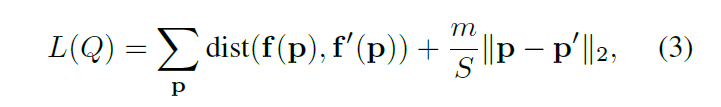
In addition, the author also tried to use the CIELAB color vector and L2 norm to write a new loss function. At the same time, the author pointed out that this is very similar to Simple Linear Iterative Clustering (SLIC). As is the following formula:
除此以外,作者还尝试用CIELAB色彩向量和L2模去计算。同时,作者指出这么做和Simple Linear Iterative Clustering(SLIC)就非常相似了。如下面公式:
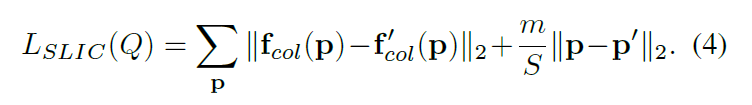
Keep simplifying the above loss function, which can be done with the one-hot encoding vector of semantic labels. As is the following formula:
继续优化上面的损失函数,可以用一键编码向量来做。如下面公式:
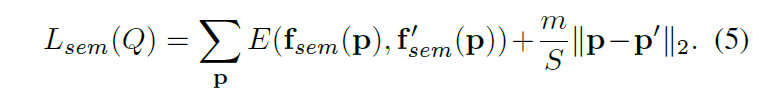
The author did not stop at this point but tried to continue to optimize the network structure. Since the full convolutional network couldn’t learn the affinity of pixels in the image, the author introduced the Spatial Propagation (SP) proposed by “Learning Affinity via Spatial Propagation Networks” in NIPS2017. Because of building affinity matrix to propagate information in the full convolutional network, the author called Convolutional Spatial Propagation (CSP). As is the following formula:
作者并没有点到为止,而是尝试继续优化网络结构。由于普通的全卷积网络不具备学习图像中像素的相连性,作者这时候引入在NIPS2017中的“Learning Affinity via Spatial Propagation Networks”。其中的Spatial Propagation(SP)可以使全卷积网络可以学习图片像素点之间的相连性。作者这里叫做Convolutional Spatial Propagation(CSP)。如下面公式:
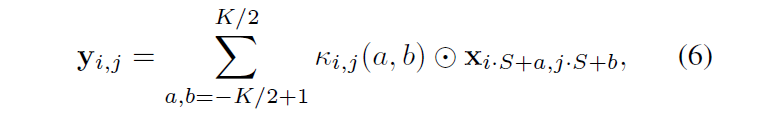
A slight adjustment is needed above the equation. It should only compare the information of the nearby 3 x 3 red boxes as mentioned earlier. As is the following formula:
这里需要稍作调整,应为之前提到只对比附近3 x 3红框区域信息。所以,如下面公式:
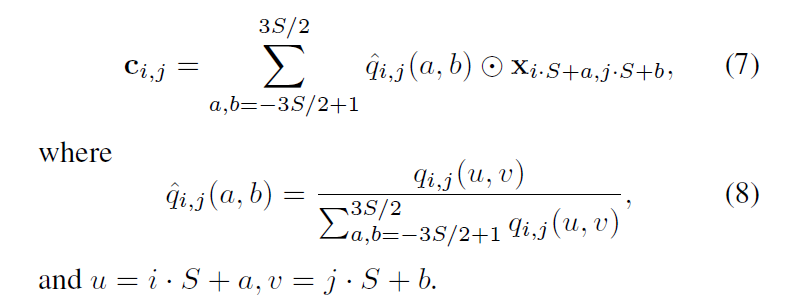
2.2 SpixelFCN + PSMNet
The second highlight of this paper is to use the generated superpixels for subsequent density prediction tasks, which can help get better results. Significantly, researchers mainly focus on stereo matching. There are four channels in the stereo matching network: height, width, disparity, and feature. 3D convolution is required to aggregate that information. And, the overall computation consumes large amounts of memory because of the extra “disparity” dimension. The general solution is to do a regression analysis of disparity to generate high-definition results. However, such processing will result in blurring of the object boundary and loss of many details.
本篇论文第二个亮点就是将生成的超像素用于后续的密度预测任务,并且有助于得到更好的结果。作者在论文中选择的是具体应用场景是立体匹配。在立体匹配网络中,有四个通道:高,宽,视差,和特征。由于这样的特性,处理这样的信息需要3D卷积来帮忙。在其中,计算视差消耗了大量的的存储空间,导致无法生成高清的结果。为了解决这样的问题,通用额解决思路是做一个视差的回归分析。但是,这样的处理会导致目标边界的模糊和细节的丢失。
The author proposed to use superpixels as intermediate information to ensure that the regression analysis of disparity will not lose too much information. Therefore, the author used the “Pyramid Stereo Matching Network” (PSMNet) in CVPR2018 as the primary architecture and combined it with SpixelFCN. The author called it SpixelFCN + PSMNet. As following:
所以,作者提出了用超像素作为一个中间信息,去保证视差的回归分析不会导致目标边界的模糊和细节的丢失。作者用了CVPR2018中的“Pyramid Stereo Matching Network”(PSMNet)作为主架构,将生成超像素的全卷积网络与之结合。这个网络就是SpixelFCN + PSMNet。如下图所示。

The overall architecture is not changed too much. It adds a downsampling/upsampling scheme based on the predicted superpixels and integrating it into existing PSMNet. Therefore, the final loss function combines the sum of the losses of the first two networks. As is the following formula:
整个的架构其实没有太大的改动,就是将上采样网络和下采样网络分开加入到PSMNet中。所以,最后的损失函数结合前两个网络的损失和。如下面公式:
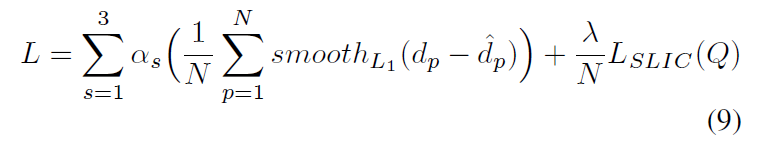
3 Experimental results 实验结果
3.1 SpixelFCN
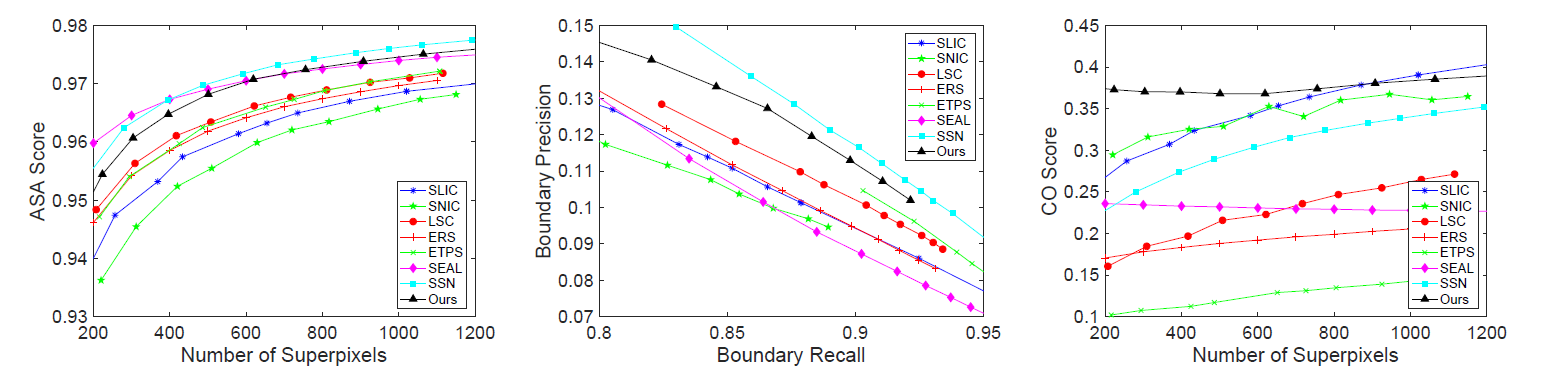
As shown in the figure below, the experiment results for superpixel generated by different algorithms on the BSDS500 dataset. The author provided three evaluation metrics. SpixelFCN and other methods are similar.
如下图,根据不同的算法生成的超像素实验结果在BSDS500数据集上。作者提供了三个测试的标准,SpixelFCN和其他方法对比都差不多。
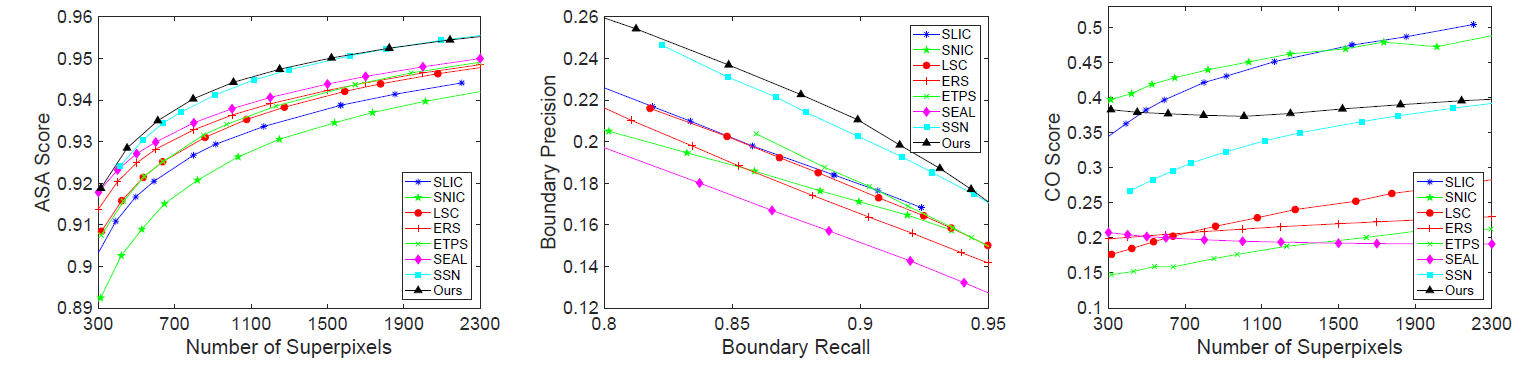
As shown in the figure below, the experiment results for superpixel generated by different algorithms on the NYUv2 dataset. The author provided three evaluation metrics. SpixelFCN gets slightly better in the second item.
如下图,根据不同的算法生成的超像素实验结果在NYUv2数据集上。还是之前三个测试的标准,SpixelFCN第二项上有小幅的提升。
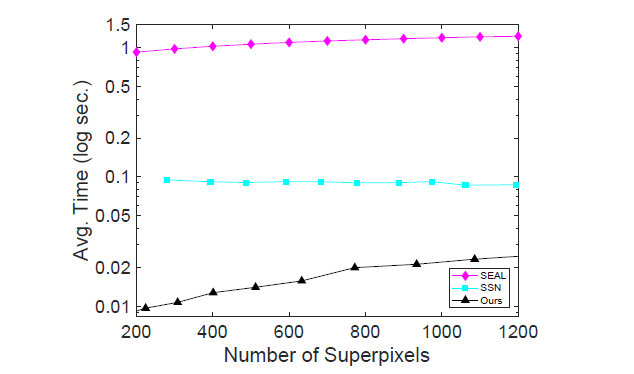
As shown in the figure below, SpixelFCN generates superpixels is faster than the previous two types. The inefficient issue is the primary problem that this paper wants to solve.
如下图,相比之前两种以全卷积网络的来说,SpixelFCN生成超像素的速度非常快,表现很突出。这也是本论文主要想解决的问题。
The figure below shows that using SpixelFCN to generate superpixels indicates that the object boundary becomes cleared and helps preserve many details.
如下图,超像素在实际图片中的结果,结果显示可以很好的处理目标边界的模糊和细节的丢失的问题。

3.2 SpixelFCN + PSMNet
As shown in the table below, the author listed the performance of SpixelFCN + PSMNet on the SceneFlow and HR-VS dataset. SpixelFCN + PSMNet can provide fewer errors.
如下表,作者列出SpixelFCN + PSMNet在SceneFlow和HR-VS的数据集上的表现。SpixelFCN + PSMNet可以提供更少的误差。

As shown in the table below, the author listed the performance of SpixelFCN + PSMNet on the Middlebury-v3 benchmark. SpixelFCN + PSMNet can provide a better result.
如下表,作者列出SpixelFCN + PSMNet在Middlebury-v3 benchmark上的表现。同样,SpixelFCN + PSMNet有更出色的表现。

As shown in the figure below, it shows the results of SpixelFCN + PSMNet. The results show that many tiny details can be well captured.
如下图,最后看看具体超像经过SpixelFCN + PSMNet的结果,结果显示可以很好的捕捉到具体的细节。

4 Note 最后寄语
Welcome to communicate more with my friends who also like computer vision.
希望和喜欢计算机视觉的朋友多多交流。
5 Reference 引用
View All 查看全部
- Fengting Yang, Qian Sun, Hailin Jin, Zihan Zhou, Superpixel segmentation with fully convolutional networks, CVPR, 2020